什么是分布式系统
关于分布式系统的定义,应该都不会陌生,它就是一些独立的计算机集合,这些计算机也称为节点,为了完成一项事务,由这一组计算节点协作完成。
而分布式还有另外一个特点,就是用户几乎感知不到它是很多节点来完成一项事务的,甚至可以说,站在用户的角度,它和集中式系统几乎雷同,用户不会觉得他/她在请求的是集中式系统,亦或分布式系统,这是分布式系统的透明性。
和传统的集中式C/S系统对比
首先看一下传统的集中式C/S系统:
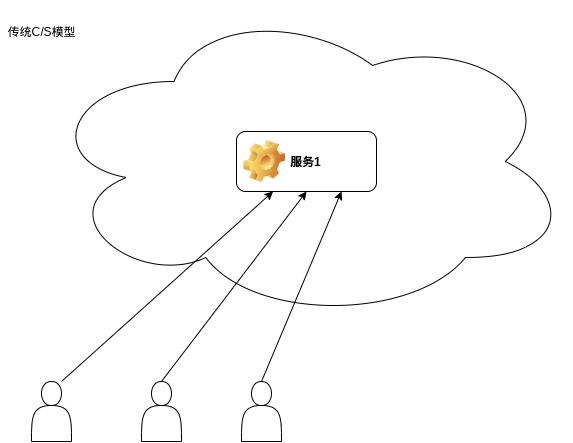
而对于分布式的系统而言,它是这样的:
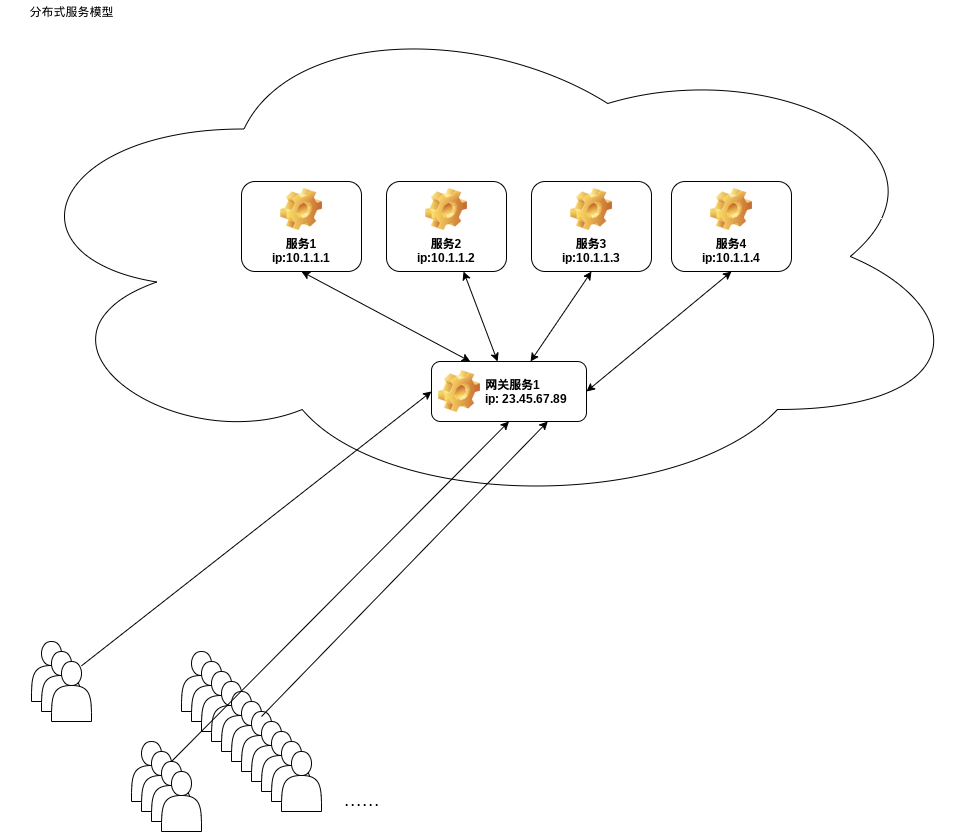
比起传统集中式C/S服务而言,分布式系统具有更强的拓展性,对于集中式的服务系统来说,需要不断升级集中式服务系统的硬件来提高系统的性能,这样做不仅成本高,而且对于整个系统的可靠性也不好;而对于分布式系统来说就简单多了,只需要增加节点即可,使系统的计算负载到新增的节点上,进而使得整个系统的性能得到提升。
相比较于集中式系统,分布式节点的性能要求可能很低,只要满足基本要求即可
对于系统的稳定性来说,分布式系统允许部分节点出现故障,而不会影响整个系统的有效性,如果整个系统出现很多节点故障,只要还有必要节点存活,这个系统就会一直有效,对外表现最多就是这个系统的性能有所下降;但是对于集中式系统来说,就没有办法这样了,它只有一个节点,这个节点崩掉了,整个系统就崩调了。
但是,分布式系统也有它的缺点,最大的问题就是数据一致性问题,因为计算需要的数据被分配到不同的节点上,如何保证各个节点对同一个数据的修改是一致的,所以,对于数据的设计就要比集中式的复杂些。
具体的技术细节
上面说了一些分布式系统的优缺点,可见分布式的优点比起它的缺点更吸引人。
但是,如果我们要去实现这样的系统,我们就不得不考虑据多技术细节:
- 分布式由许多子服务运行在这些节点上的,但是如何来划分这些子服务呢?
- 在任何跨站服务同步都少不了协同通信,如何设计一套同步通信呢?
- 上面说的数据一致性问题,应该如何解决呢?
- 分布式系统就是为了可以拓展,那么如何设计来达到可拓展性呢?
如果上来我们就去解决这些问题,会非常棘手,不过好在这些技术都存在很多设计模板,和很多开源中间件,因此我们不用从零开始来设计这套系统,不然又要从入门到放弃了。
在设计这样的系统时,我们还是另辟蹊径(或者说是我熟悉的一个领域),这种分布式在游戏服务端中很常见,说到底其实也很简单,只有那么几个技术(其实也在更新发展中,也许和我的版本有些许不同),因此我们只要借鉴游戏服务框架的设计思想即可也可设计一个我们自己的分布式服务系统。
对于分布式系统,解决并发问题的核心是数据通讯问题,如果在同一个节点里,可以很容易实现数据共享,但是它的效率低下,实现复杂,而且通用性不强,对于节点与节点之间的数据共享就不得不借助套接字了;其次一个方案就是消息传递了,这种方案最常见了,各种开源的中间件,可以说已经是默认方案了,消息传递适用场景也更加广泛,可以是线程之间的同步,进程之间,或者是节点间,它都可以派上用场。
Actor模型
说到消息传递,我们就要来复习一下Actor模型。
可以参考一下维基百科的描述:Actor Model
什么是 Actor 模型
Actor模型是一个基本的计算单元,它可以接收消息,并且基于消息执行计算,并将计算结果以消息的形式返回给调用它的Actor,Actor之间相互隔离,他们之间不共享资源。
Actor的本身是状态机模式的进一步封装,它由三部分组成:状态(State),行为(Behavior),邮箱(MailBox)
以上三部分很好理解,状态和行为是状态机的必要元素,邮箱是和外部Actor交互的通道。
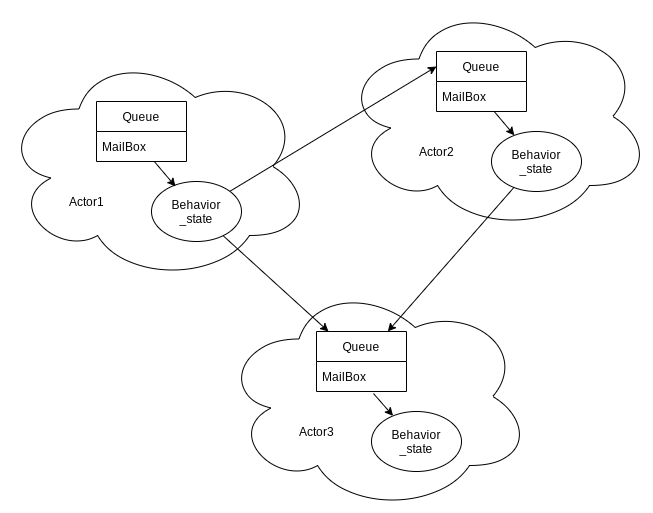
由此可见最上方展示过的那张图中的"服务N",这些都可以抽象化成为Actor模型,每个服务可以对应一个或者多个服务。
状态机模式
Actor模型用到了状态机模式,状态机模式是一种很常见,很实用的设计模式。
状态机包含最基本的四要素:状态(State),事件(Event),动作(Action),变换(Transition)
- 状态(State):当前状态机的状态
- 事件(Event):触发操作的条件
- 动作(Action):所触发的操作
- 变换(Transition):从一个状态变成另一个状态的转化表
一个状态机至少包含两个状态:开始态,结束态
状态机是刚开始的时候,设置为开始态,然后,根据输入的事件触发进行下一个状态,每一个状态都有对应的操作(动作),每种状态的变换,都是根据变换条件来设定的,一直到状态机走到结束态,这个状态机就属于终结了。
由此可见,我们可以把状态机想象成一个黑盒,它接收任何可能的输入,各种不同的输入会触发黑盒内部的状态改变,从而进行下一步操作,从而状态机的维护了它内部的信息隔离,状态安全的优点,也便于外部使用它。
而Actor模型就是内部嵌套着这样的一个状态机,再加一个邮件队列,从结构看来,非常简单明了。
MongoDB
在说到分布式系统一个很令人头疼的问题那就是数据一致性问题了,虽然为了达到分布式系统数据一致性的方法五花八门,但是这里我推荐一款非常适用的方案,那就是这款MongoDB数据库,这个基于分布式文件存储的数据库天生为了分布式系统而打造的,很多大型分布式游戏服务端用的都是这套系统。
MongoDB提出文档(Document),集合(Collection)概念,其数据模型结构类似于JSON,非常适合实际环境下读写,其次MongoDB支持数据集分片的功能,从而可以把数据分摊到多个用于存储数据的节点上,最后,因为它的数据模型是基于面向对象的,所以可以表达很丰富,层次较多的数据结构。
Redis缓存
在我们的分布式系统里面,Redis的作用是用来缓存数据的,因为我们的Actor它要操作数据库进行读写操作,这里的Actor可以是一个专门负责数据存储的Actor,它来读写数据库,读写数据库如果是同节点的数据库,那速度应该不会很慢,但是仍然不如Redis这种内存数据库的快速,而往往有一种更加复杂的情形,那就是读取MongoDB实际上不在本地,而是在另一个节点上,这读写一次数据还要经过网络,所以时间较长,这时Redis的角色就更不可或缺了。
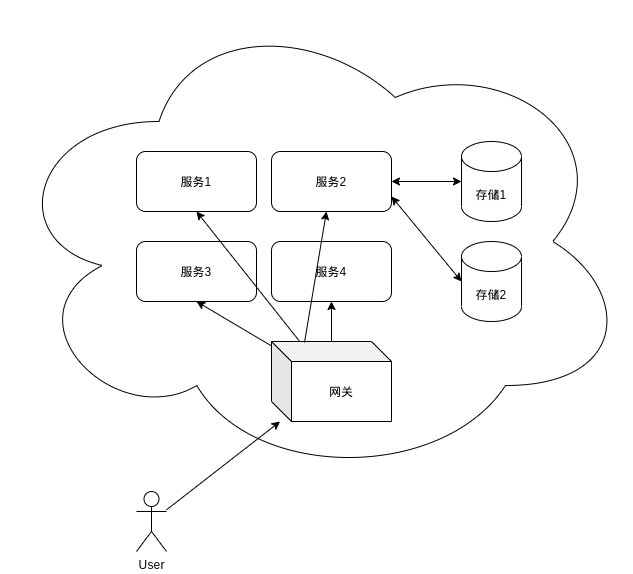
分布式适用场景
分布式系统适合用户量很大,数据存储量庞大的场景,对于庞大的用户接入,如果是集中式的服务系统,那么它的负载压力就会很大,很容易触及性能瓶颈,而去提升它的话,所要支出较大,而且灵活性也很差,但是对于分布式系统而言,系统可以存在多个网关服务节点,用户只需要接入网关节点,把网关节点当作服务节点用即可。
网关节点则是从其他节点获取实际请求的资源,得到结果后,把它返回给用户。
通常来说这样的分布式系统是存在一个内部网络中的,它是由很多节点组成的系统,系统中的网关节点是存在公网IP的,可以被外部访问,而内部其他的功能服务节点,视其功能可以不对外开放访问,它只会把结果交给网关服务节点,网关会把数据请求发给对应的内部服务节点。
技术总结
这种分布式的服务系统相对来说可以接收很大的接入量,比如200k,1000k都可以做到,只需要增加网关节点即可,数据量也可以变得非常庞大,这时我们只需要增加MongoDB的数据分片即可。总的来说,就是性能不够增加节点即可。
这里我们所需要的技术全部都是非常明了,中间件也非常完善,唯独在Actor模型,和服务分类上面稍作设计就可以达到我们所需要的目的,尤其在同构的服务上,如何实现协作要精心设计一下。
这里的技术概要就写道这里,我会在下一篇技术博文使用具体的设计工具,并且编写代码,制作一个微型的分布式服务系统。

