使用 LangChain 构建智能体实战
使用 LangChain 构建智能体实战
本文从 LangChain 基础入门开始,从基础智能体(Agent)开始,到构建一个生产级的智能体系统,所需要的知识概念。
传统的 ChatBot 只能进行聊天,人工智能反映在知识输出上,但是这种智能并不能自出决策,并使用工具调用。虽然后来的 AI 大厂发展出了工具集概念,但是对于很多业务的特殊性,他们的工具能力非常有限。而构建智能体系统,其业务核心不是LLM的模型,而是在于业务的编排层,LangChain 就是这样的编排层的框架,非常便于实现智能体系统。
一、什么是 LangChain Agent
1. Agent 的核心组成
在 LangChain 以及更广义的 AI 系统中,Agent 并不是一个“会聊天的模型”,而是一个能够理解目标、做出决策、并采取行动的系统。一个实用的 Agent,通常可以抽象为三个核心组成部分:
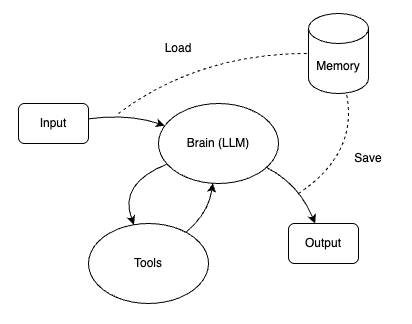
Agent ≈ 大脑(Brain) + 手(Hands) + 记忆(Memory)
大脑(Brain):负责思考和决策
大脑对应于大语言模型(LLM),它和聊天式应用存在显著不同,它的职责不是回答问题进行知识输出,而是:
- 理解用户意图
- 拆解任务步骤
- 决定是否调用工具
- 调用哪个工具,以及如何调用工具(参数)
手(Hands):让 Agent 能够“做事”
手对应于 Tools(工具),工具的本质是可以被模型调用的,并且觉有明确功能的,一种模型外部提供的能力。
常见的工具有:
- 搜索引擎(查阅资料)
- 计算(数值计算,统计等等)
- API 调用(查订单,发邮件等等)
- 数据库/向量检索(RAG)
一般来所,Agent 的能力上限,往往不是由模型决定的,而是由工具决定的。
记忆(Memory):让 Agent 有“上下文意识”
Agent 在启动后,和 ChatBot 聊天应用类似,随着问答的继续会产生大量上下文的内容,如果每次 Agent 启动后不能加载之前保存的上下文内容,那么它就会从 0 开始,对于复杂业务流程,就导致不能中断后继续,所以让 Agent 能够保存上下文能够记忆是十分必要的。
Agent 的记忆通常有:
- 短期记忆:当前上下文对话内容,一般存储在内存中。
- 状态信息:中间结果,已经完成的步骤。
- 长期记忆:用户偏好,历史行为。
这里的记忆(Memory)并不等同于把对话上下文全量塞入 Promt 提示中,真正的记忆是有选择性地记住重要的信息。
以上三者的协作通过一个核心循环组成,如下图示。
2. LangChain 中 Agent 的基本运行流程
在 LangChain 中,Agent 并不是一个可以直接调用的对象。真正负责驱动 Agent 运转的,是 AgentExecutor。
在了解 AgentExecutor 之前,我们先看一个例子,这个例子是没有使用 LangChain 的 Agent ,而是尝试手动调用大语言模型来完成工具调用,图示如下。
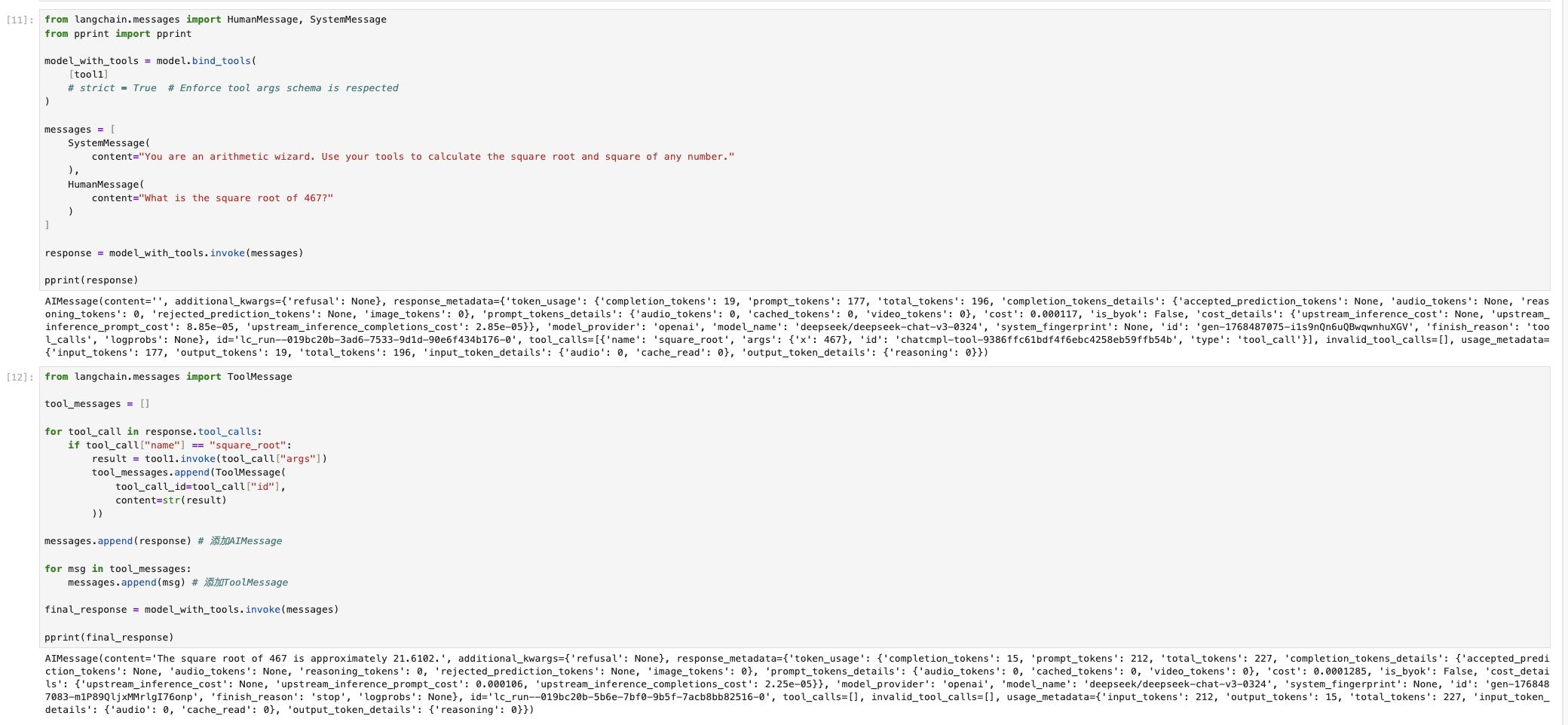
可见为了和大语言模型进行互动,对于工具的使用,需要非常繁琐的操作(把工具调用ID和手动调用结果,全部添加到上下文的消息里面),这样大语言模型才能使用工具生成的结果,而 LangChain AgentExecutor 是一种高层次的封装,它不仅可以解决以上问题,更有解决其他错误与异常问题。
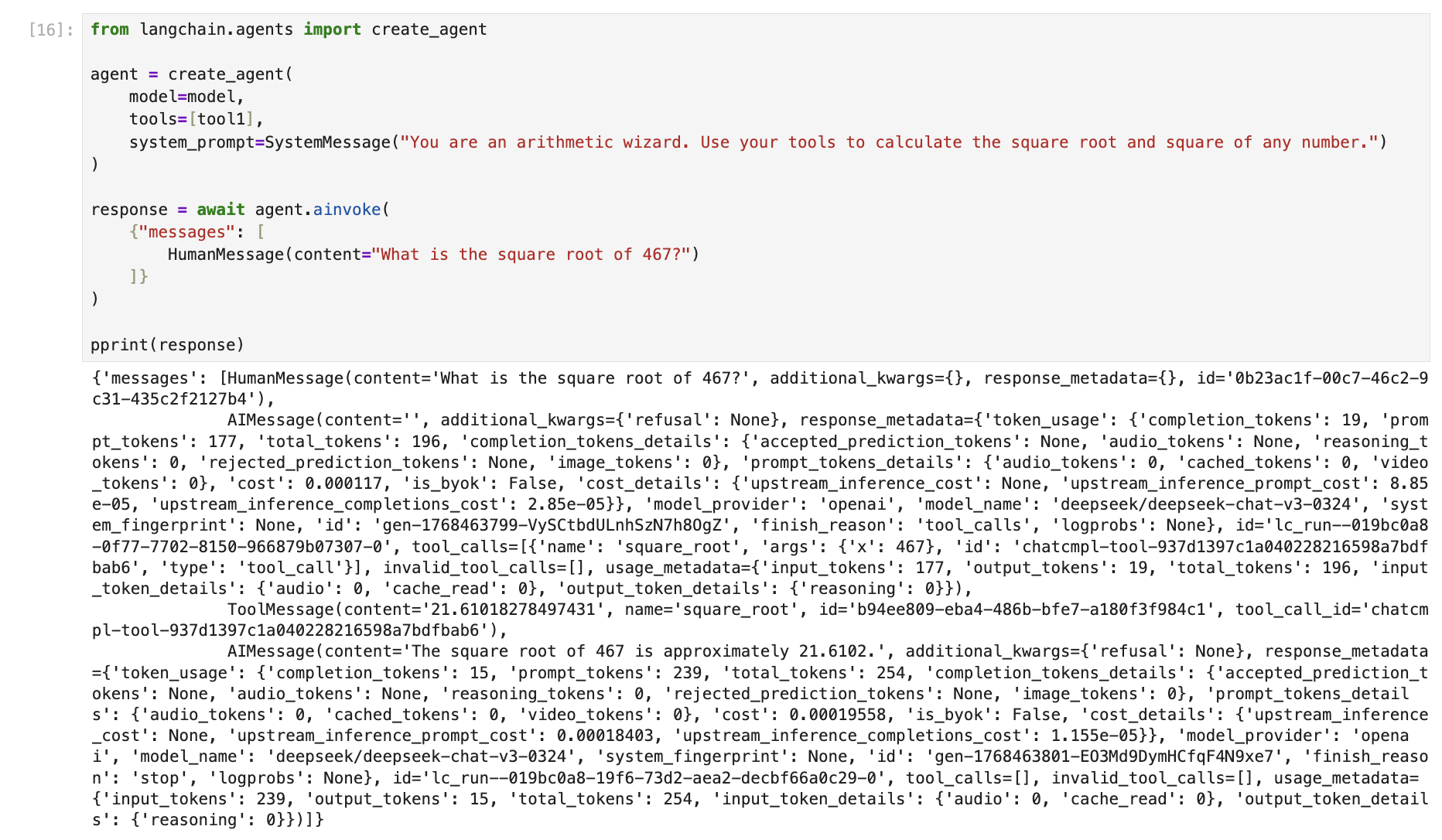
如上所示,Agent 下所有的繁琐都被它自动处理掉了,我们只需关心流程和结果即可。
首先看看 AgentExecutor 主要四类职责:
1. 驱动 Agent 思考的循环
Agent 的核心不是一次模型调用,而是一个循环过程:
- 将当前输入 + 上下文交给 Agent(LLM)
- 解析模型输出,判断下一步是:
- 直接给出最终答案
- 还是调用某个工具
- 如果需要调用工具:
- 执行工具
- 获取结果
- 把结果反馈给 Agent
- 进入下一轮思考
这个循环本身不是模型做的,而是 AgentExecutor 做的。
2. 工具调用的编排与执行
AgentExecutor是智能体的核心,它的职责如下:
- 根据模型输出,匹配对应的 Tool 工具
- 校验参数的合法性
- 执行工具函数
- 获取工具函数结果或异常
- 对结果进行封装
这里可见,AgentExecutor自动帮我们做完了上述 Jupyter 演示图上的步骤,而且 AgentExecutor 的做法更加规范和优雅。
3. 管理上下文与中间状态
此外,AgentExecutor 除了封装工具调用的流程步骤外,它还在会话过程中维持了当前会话历史,中间推理结果,中间推理结果,Memory内存读写,以及执行的步骤记录。
这些信息也是决定了 LLM 能够看到的内容,Agent 是否会陷入死循环,以及调试和观测用途。
4. 运行控制与保护机制
在真实系统中,AgentExecutor 还有一些兜底职责,以起到控制保护的作用。
这些职责包括:
- 最大迭代次数(防止死循环)
- 超时控制
- 错误处理与重试
- 日志信息
二、从 0 到 1:构建一个基础 Agent
上面已经解释了一些 LangChain Agent 的基本概念,以及它内核的基本结构原理。
那如果要构建一个这样的 Agent 智能体思路也是清晰可见,按照 Agent 核心组成来做,让 Agent 成为能够思考,并且会用工具的实体,分为三部来完成。
1. 选择基础模型(LLM Model)
模型的选择对于 Agent 至关重要,一般分为两种类型模型:
- Chat 模型
- Instruct 模型
这两种模型区别很大,Chat 模型为多轮对话优化,擅长理解上下文、角色和对话状态,而 Instruct 模型为执行指令优化,擅长一次性把任务做对、做稳。
例如,deepseek-chat为 Chat 模型,mistral-small-24b-instruct 则是 Instruct 模型。
对于 Agent 重要的能力分别是指令遵循,以及 Tool Calling 的稳定性。
2. 为 Agent 赋予工具能力(Tools)
Tool 的本质是一个有描述的函数,每个 Tool 都有一个对应的 Tool Schema,用于描述 Tool 函数,它会直接影响到 Agent 的行为。
Tool 的设计有讲究的,设计的不好,Agent 会呈现出乱用工具的现象(通常 Tool 函数的描述在 Tool Schema中要说明清楚,多个 Tool 函数时,各个函数的职责要分工明确)。
通过以上三步,我们发现一个可以工作的 Agent 必要具备因素:
- 可以思考
- 有工具
- 可以理解上下文
下图演示了一个 Tool 工具的定义。

这样定义好的 tool1 就可以被模型或者智能体直接拿去引用。
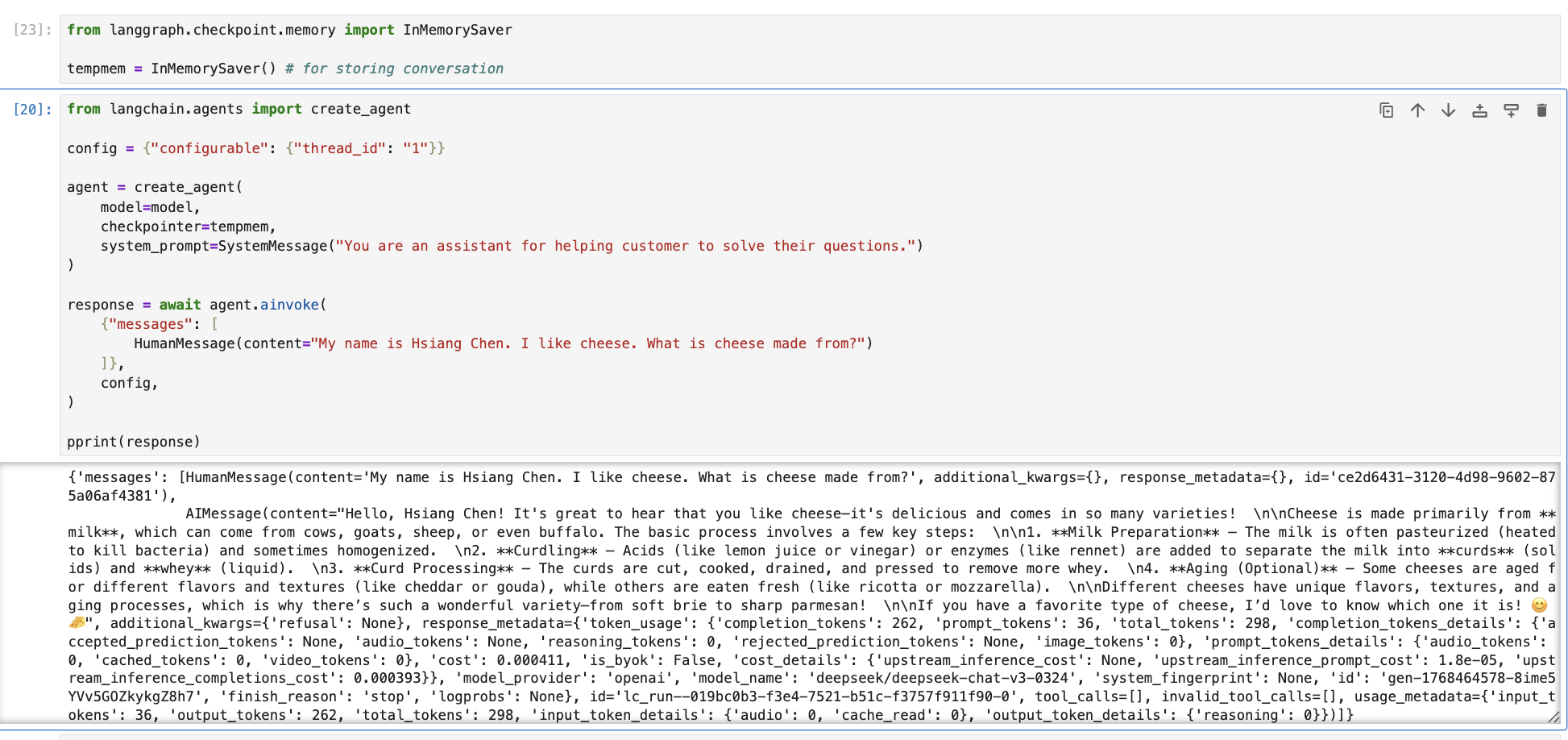
3. 短期记忆(Short-Term Memory)
短期记忆保证了 Agent 可以执行中断,并在后续恢复运行并且不会丢失之前的结果与信息,因为大语言模型 LLM 都是无状态的,如果不提供旧的聊天历史,模型是不知道的。
这里的记忆是存储在内存中的短期记忆,不会落盘保存的,它用于提供给大语言模型 LLM 的目的,对于落盘保存的属于另一个范畴:向量数据库。
下图演示了如何建立一个短期会话存储,并进行使用。
三、从“单体 Agent”到“智能系统”
下面从单体 Agent 转变到系统级的角度。
1. 上下文和状态的长期运行
这里的上下文会涉及到概念区分:Context,Prompt。
什么是 Prompt
Prompt 是模型的一次调用输入,生命周期只存在于当前这次。
什么是 Context
Context 是 Agent 在多个步骤、多轮决策中共享的信息集合。
Context 的内容可以是和模型的历史对话,中间推理结果,调用外部工具的结果,执行的动作,当前任务状态等这些信息。
LangChain 中也支持一种特殊上下文数据的定义,下面举例说明,如何在 Agent 中设置 Context。
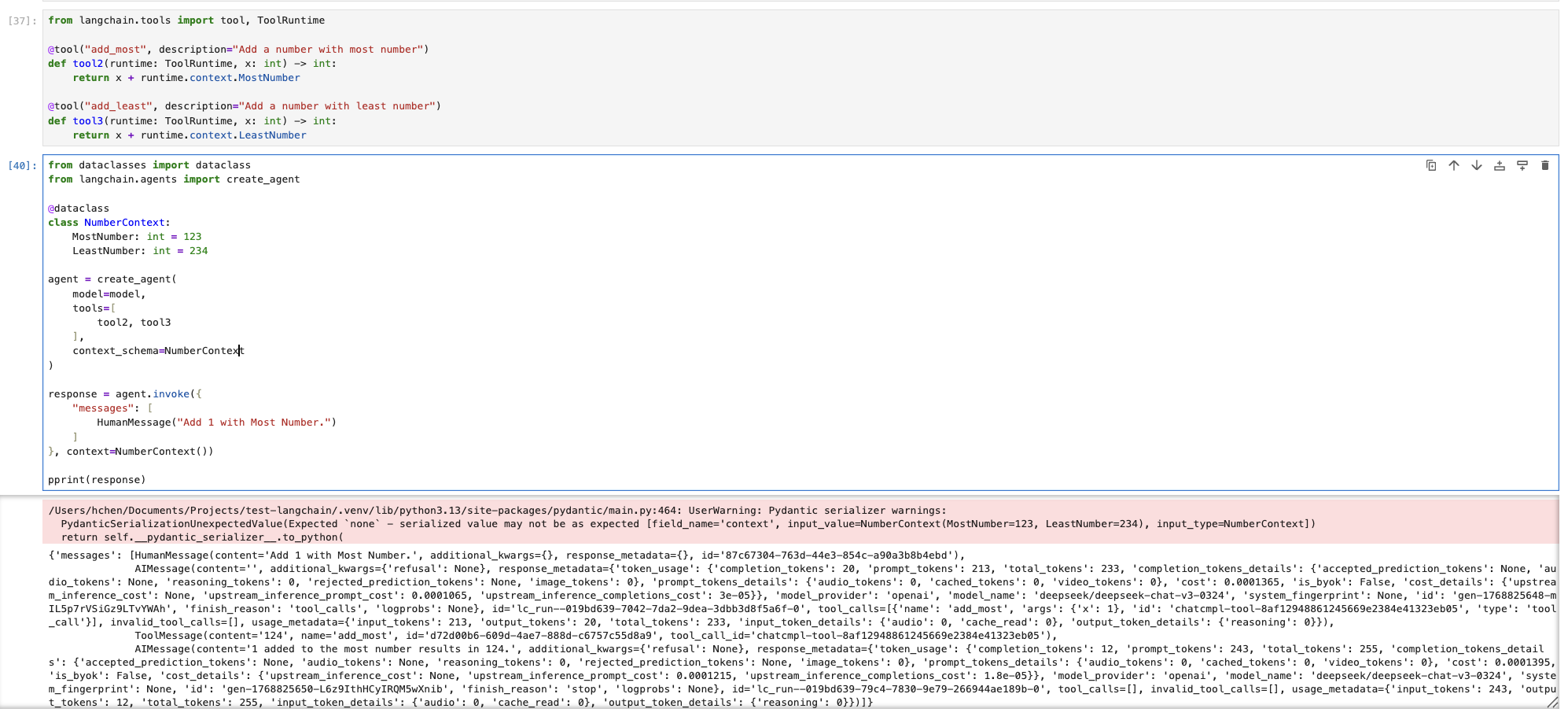
而对于 Agent 运行状态是用于表示当前阶段,以及判断下一步行为,有了状态就可以表示一个持续运行的系统(和状态机一样)。
那么在 LangChain 中如何定义 Agent 的状态呢?
LangChain 支持一种特殊 Agent 状态的定义,可以通过新建一个带状态描述 Agent 来实现(和 Context 类似),如下图示例。
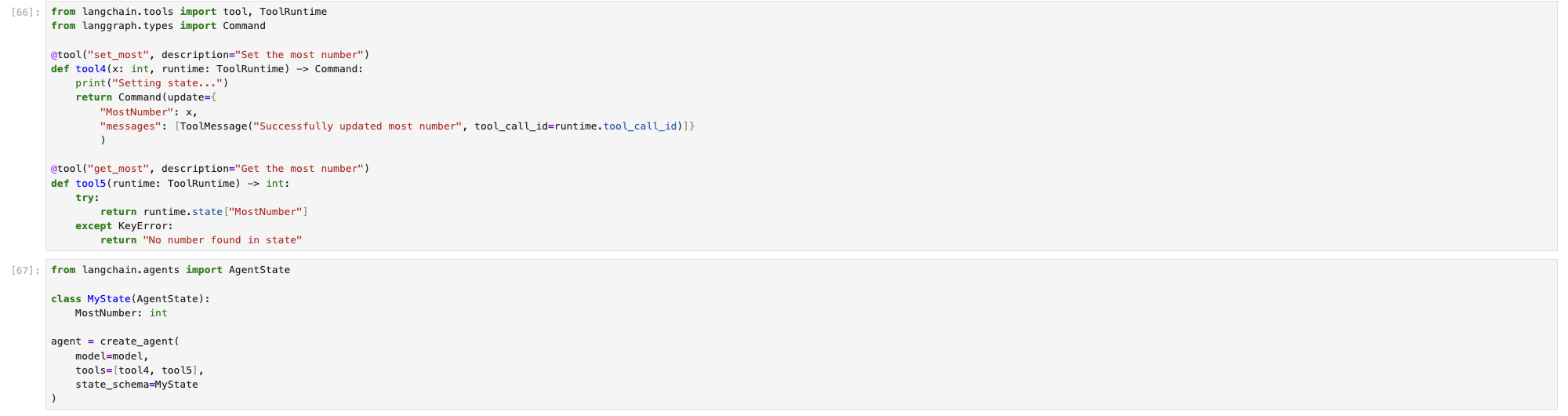
通过两种调用方式都能达到效果。
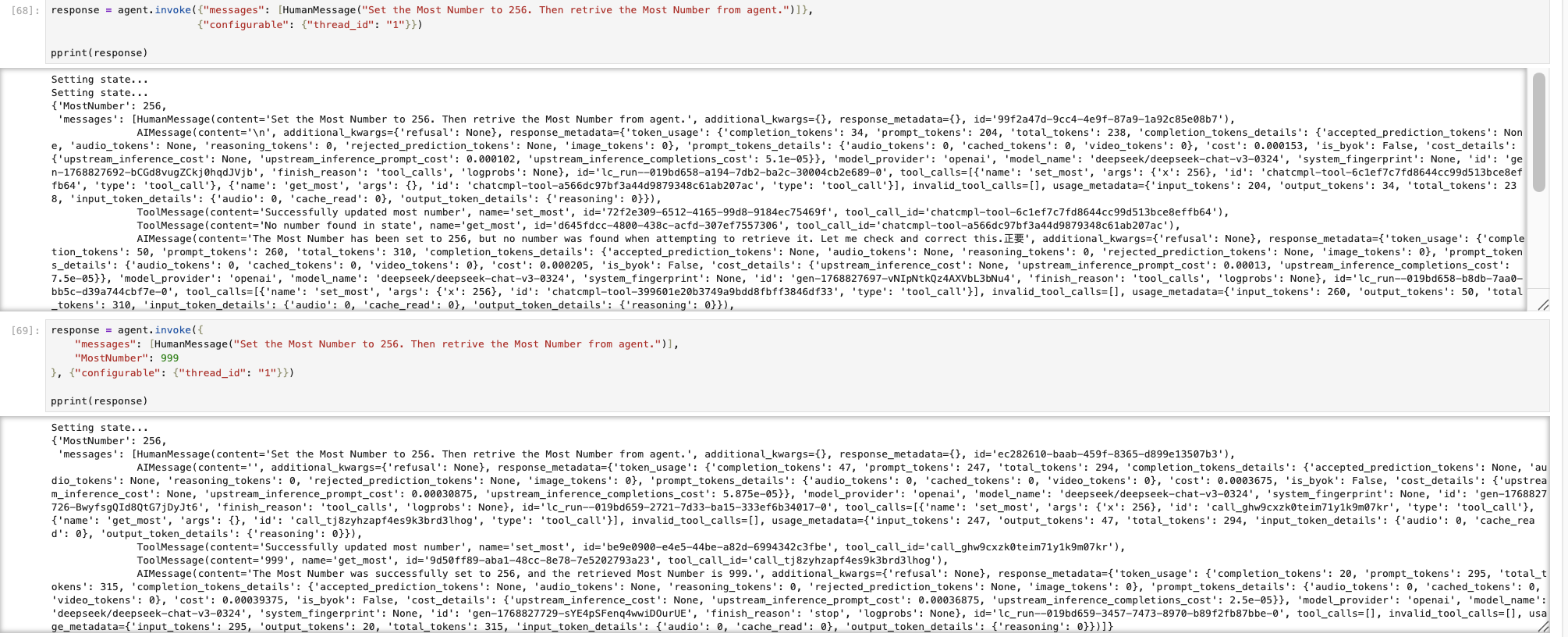
值得注意的是 LLM 是 State 的消费者,而不是拥有者。
2. Model Context Protocol(MCP)介绍
随着 Agent 从“单模型 + 少量工具”演变为“多模型 + 多工具 + 长期运行”,那么一个问题开始变得无法回避:
Context 到底应该如何被组织、传递和理解?
这正是 Model Context Protocol(MCP) 想要解决的核心问题。
Agent 系统的工程痛点,与 MCP 的解决方法:
1. 数据孤岛与“上下文”碎片化
- 痛点: AI 往往处于“信息真空”状态。为了让 AI 了解项目背景,你不得不手动复制粘贴文档,或者忍受 RAG(检索增强生成)复杂的搭建过程。
- 解决: MCP 允许 AI 实时、按需地从本地文件、数据库或第三方 API 中提取最相关的上下文,而无需反复上传数据。
2. 极高的集成维护成本
- 痛点: API 经常变动。如果 GitHub 更新了 API,你所有集成了 GitHub 的 AI 工具可能都会挂掉。
- 解决: 开发者只需维护一个 MCP Server。一旦这个 Server 更新,所有支持 MCP 的 AI 客户端(如 Claude Desktop、Cursor编辑器)都能直接使用更新后的功能。
3. 安全与权限控制的混乱
- 痛点: 给 AI 授权通常意味着要把 API Key 交给第三方应用,存在安全隐患。
- 解决: MCP 支持本地运行的 Server。你的敏感数据(如本地代码、财务报表)不需要上传到云端进行处理,MCP Server 可以在本地运行并只向模型提供必要的摘要信息,保持了数据所有权。
4. 缺乏统一的工具调用(Tool Calling)标准
- 痛点: 不同模型的 Function Calling 格式略有不同,切换模型往往意味着重写工具逻辑。
- 解决: MCP 定义了统一的资源(Resources)、提示词模板(Prompts)和工具(Tools)交互标准,让“模型驱动工具”变得像调用函数一样简单且通用。
MCP 是一场关于“解耦”的革命。它把“模型的能力”与“数据的获取”分离开来。
在 LangChain 中要引用一个 MCP 的话,非常简单,示例如下图。
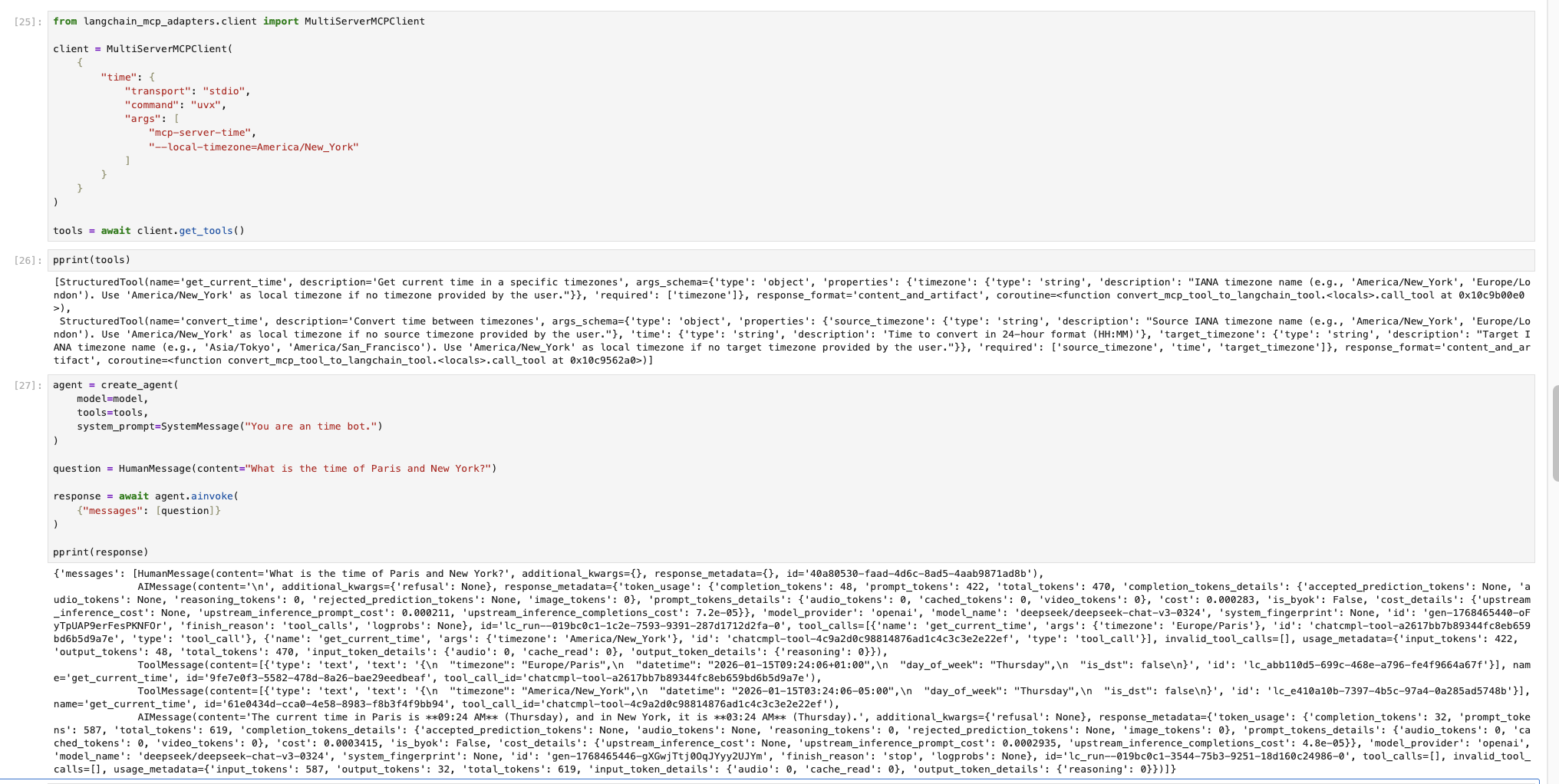
上图先是启用了一个时间获取的 MCP 服务,然后让 Agent 去获取它的工具去使用。
关于如何设计并制作 MCP 服务,请参考 MCP 入门教程,MCP协议可以参照这里。
3. 多 Agent 协作(Multi-Agent Systems)
为什么单 Agent 不够?
在 Demo 阶段,一个 Agent 往往看起来已经“足够聪明”,但一旦进入真实场景,单 Agent 的问题会迅速暴露出来。
1. 单 Agent 的问题
这些问题包括如下几类:
-
复杂任务导致职责失控
需求理解,任务拆解,调用工具等操作导致上下文越来越长,导致推理路径也越来具有不确定性,结果的不确定性。
-
推理、执行、校验混在一起
三个元素混合,一旦出现错误,问题定位非常困难,相当于工程里出现的没有职责边界的服务。
-
可扩展性和可维护性极差
例如如果给系统添加审查能力,或者人工介入能力,单 Agent 意味着可能要重写 Prompt,并且需要重试所有的路径,风险巨大。
-
安全与成本问题
单 Agent 只有一个服务,可能会获得很高的权限,但是实际上可能并不一定需要这种高权限,难以精化,为系统安全和成本都带来压力。
2. 多 Agent 的设计
多 Agent 的核心思想:拆分职责,而不是堆能力。
常见的多 Agent 协作模式分为如下几种:
-
Planner / Executor 模式
在这种模式下,Planner Agent 负责理解目标,拆解任务,并生成执行计划,而 Executor Agent 则是按照计划调用工具,专注于执行。
-
Reviewer / Worker 模式
在这种模式下,Reviewer Agent 进行任务的结果审查,找出问题,并提供修改意见,最后决定是否通过,而对应的 Worker Agent 则是完成主要任务,生成初稿或者结果。
-
Manager / Sub-agent 模式
在这种模式下,Manager Agent 负责分析任务类型,决定调用哪些子 Agent,并最终汇总结果,其下的 Sub-agent 负责某个子模块/自领域的处理能力,工具集和上下文相互独立。
以下示例了一个 Manager / Sub-agent 模式的例子。
这个例子是一个负责进行游戏玩家监管的 Agent,当检测到作弊玩家后,Agent 会自动发送通知信息,并把玩家在系统中禁用。
首先,定义工具操作函数(这里都是 mock 操作),并定义子 Agent (分别是发送通知信息和禁止用户)。
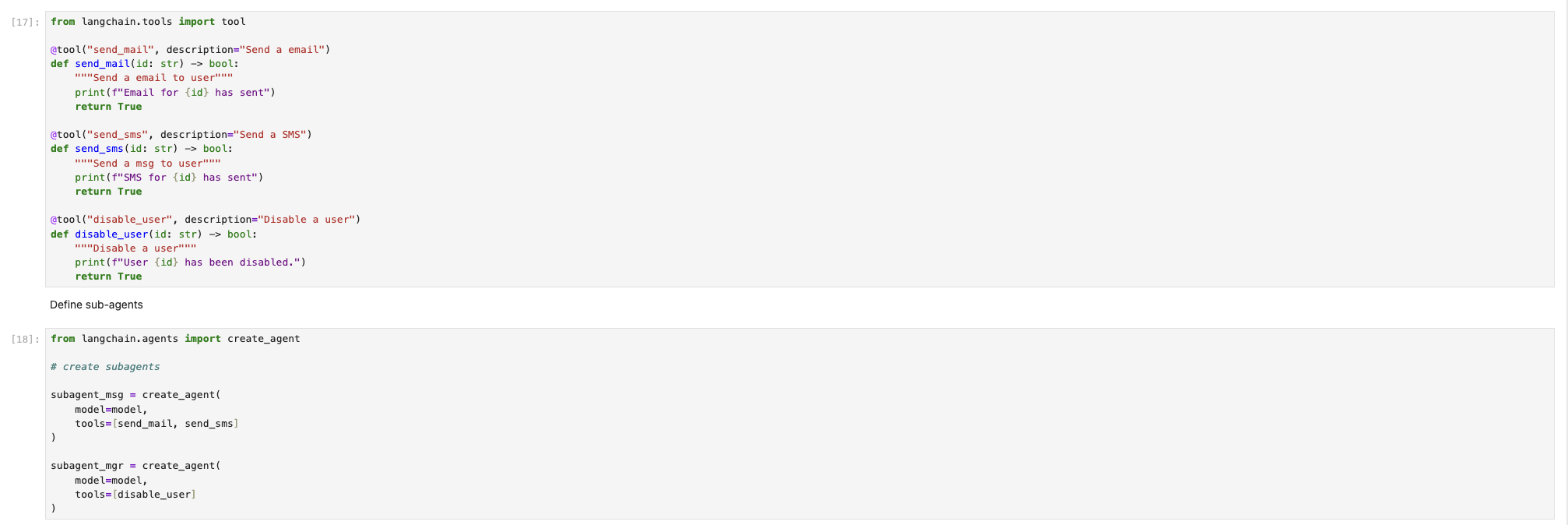
然后再定义 Manager Agent (这里对应main_agent)
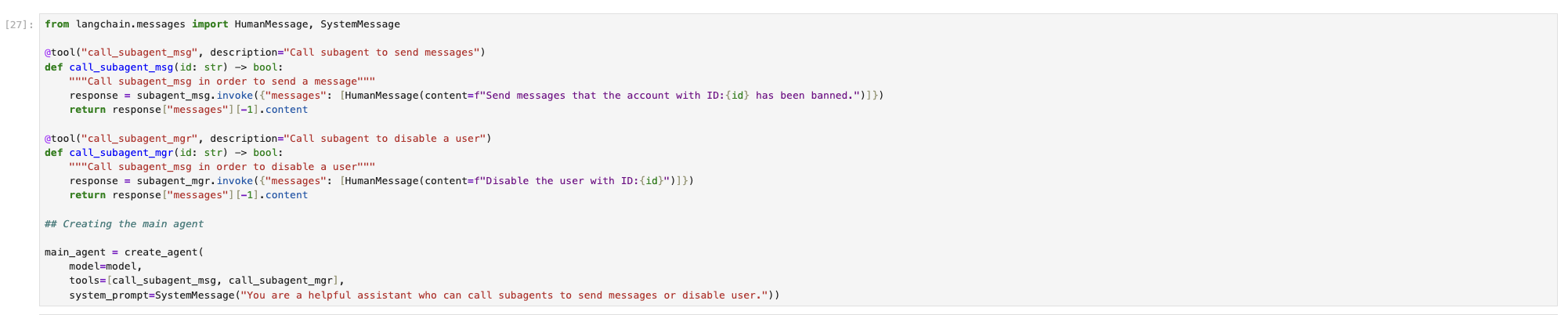
调用 Manager Agent 告诉要进行的操作,效果如下图。
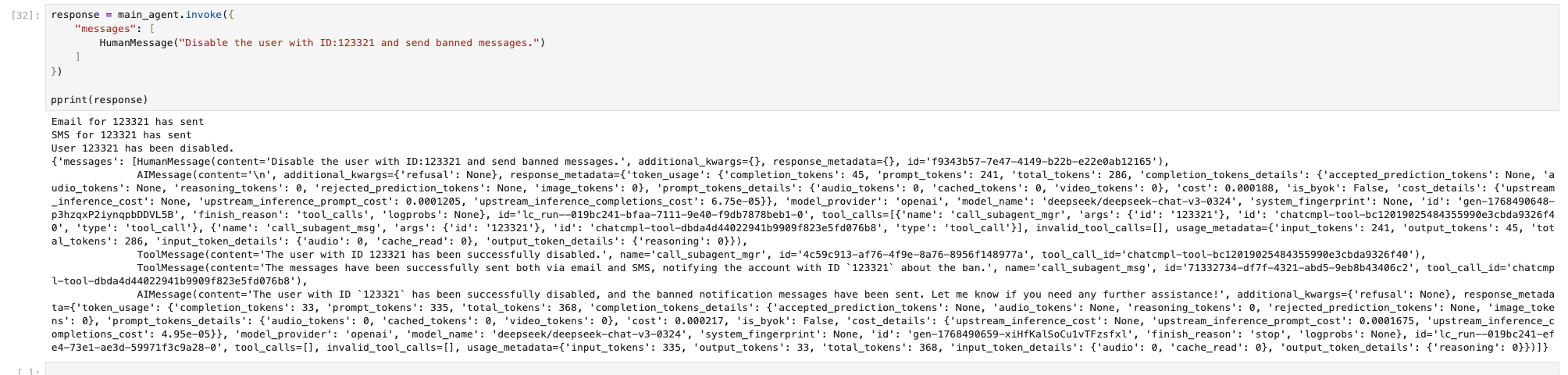
可见在这种模式下,Agent 的调用与效果如期望相符。
四、迈向生产:构建可上线的 Agent
构建一个 Agent 系统,不是仅仅能跑就可以了,更关键的是能够长期稳定运行,本节将从生产环境下讲述需要关注的方面。
1. Agent Middleware 介绍
传统计算机由 CPU ,内存,和外设组成,把这三者联动起来的是计算机的操作系统。按照这个类比的话,LLM 是 CPU ,不同的 Agent 相当于不同的应用程序,而 Agent Middleware 就相当于 Agent 系统的操作系统,它是不同 LLM 和 Agent 的管理组件,假设没有这些 Middleware ,Agent 系统将只能手动管理,不仅管理繁琐,难以复用,拓展性受限,还很容易出错,所以说 Agent Middleware 是 Agent 系统的操作系统。
Agent Middleware 通常可以分为如下几类:
-
运行时管理
这类主要为了解决 Agent 步骤如何推进,失败了如何恢复的问题。
-
上下文记忆
这类是决定哪些信息应该进入上下文,保证 Agent 不会失忆,同时上下文过长时,如何进行压缩。
-
工具能力类
这类聚焦于工具如何被安全地调用,如果工具调用失败了,应该如何处理这些问题。
-
流程协作类
这类是集中多步任务如何拆解,以及多 Agent 如何协作的问题。
-
安全治理类
这类是 Agent 的安全治理,Agent 在系统中不可以乱来,包括风险操作的拦截,以满足企业合规性要求。
-
观测运维类
这类用于监控与调试用途,便于错误复现并进行修复,以及日常指标观测。
这类做了一张和计算机类比的图标以比较参考:
| Middleware 类别 | 类比 OS | 核心职责 |
|---|---|---|
| Runtime & Execution | Kernel | 执行与生命周期 |
| Context & Memory | Memory Manager | 状态与记忆 |
| Tool & Capability | Syscall | 能力调用 |
| Control Flow | Scheduler | 流程与协作 |
| Safety & Governance | Permission System | 安全合规 |
| Observability & Ops | Debug / Monitor | 调试与运维 |
2. 长对话和上下文压缩
长对话和上下文压缩是一个很现实的工程问题,随着对话次数增加,这个问题就会呈现出来。过长的对话会消耗大量的 Token 数量,导致系统成本上升。一般方法是忘记掉无效的信息,例如工具调用的中间结果,更常规的方法是是对历史会话做摘要,这样以来,系统会自动总结出历史记忆,仅以简短的信息概括,而不会产生 Agent 失忆。
如下图示例说明在 LangChain 中,如何使用 SummarizationMiddleware 来完成长对话的上下文压缩。
首先,定义一个支持短期记忆,并且使用 SummarizationMiddleware 中间件的 Agent,然后开始问答。
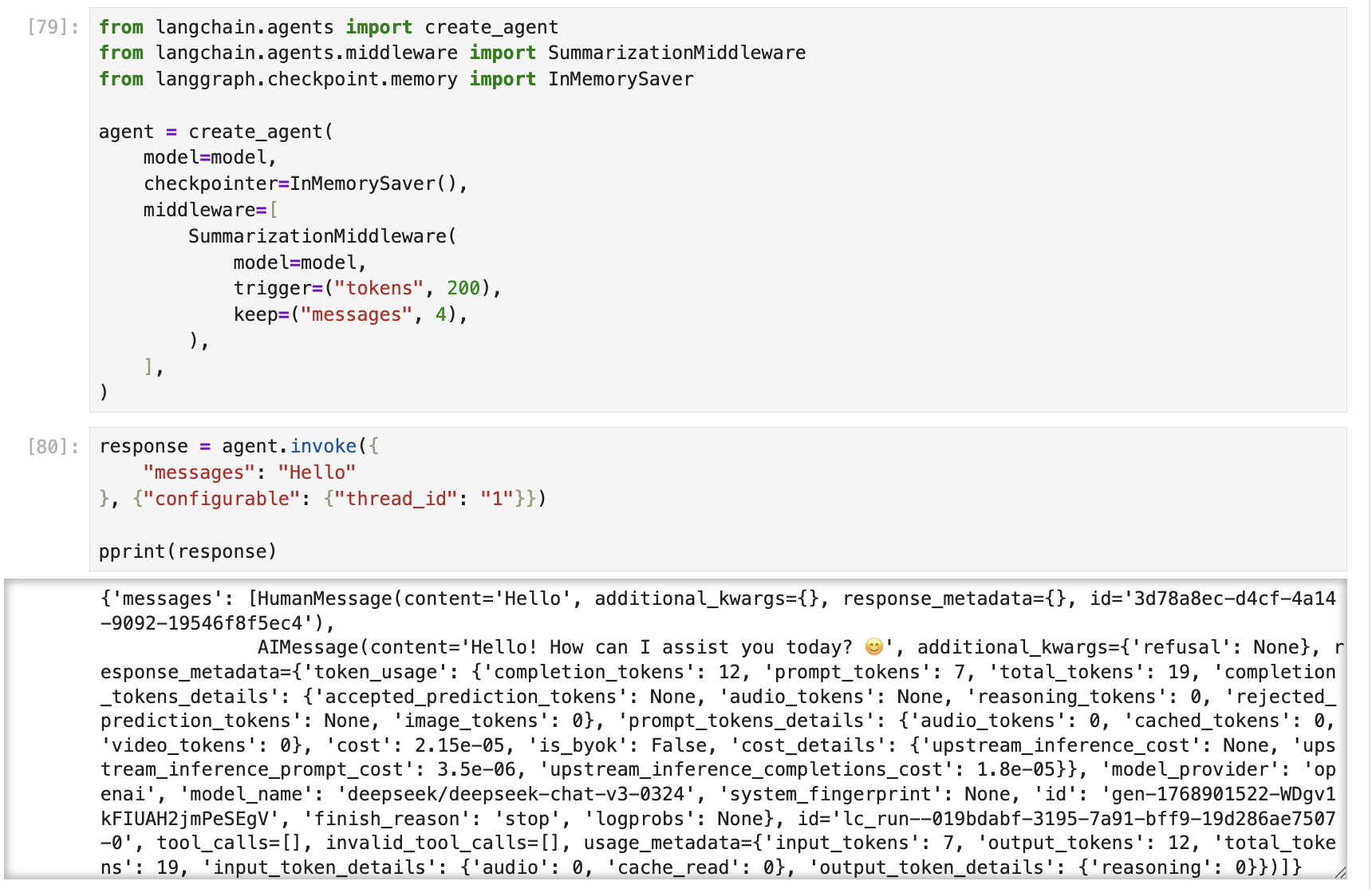
可见经过多轮问答后,达到设定的阈值后,messages中的字段就会被压缩成概要描述。
3. Human-In-the-Loop(HITL)
生产环境下,会遇到一些高风险的决策和操作,因此必须需要人为进行干预,这也是 Agent 系统安全合规的保证。
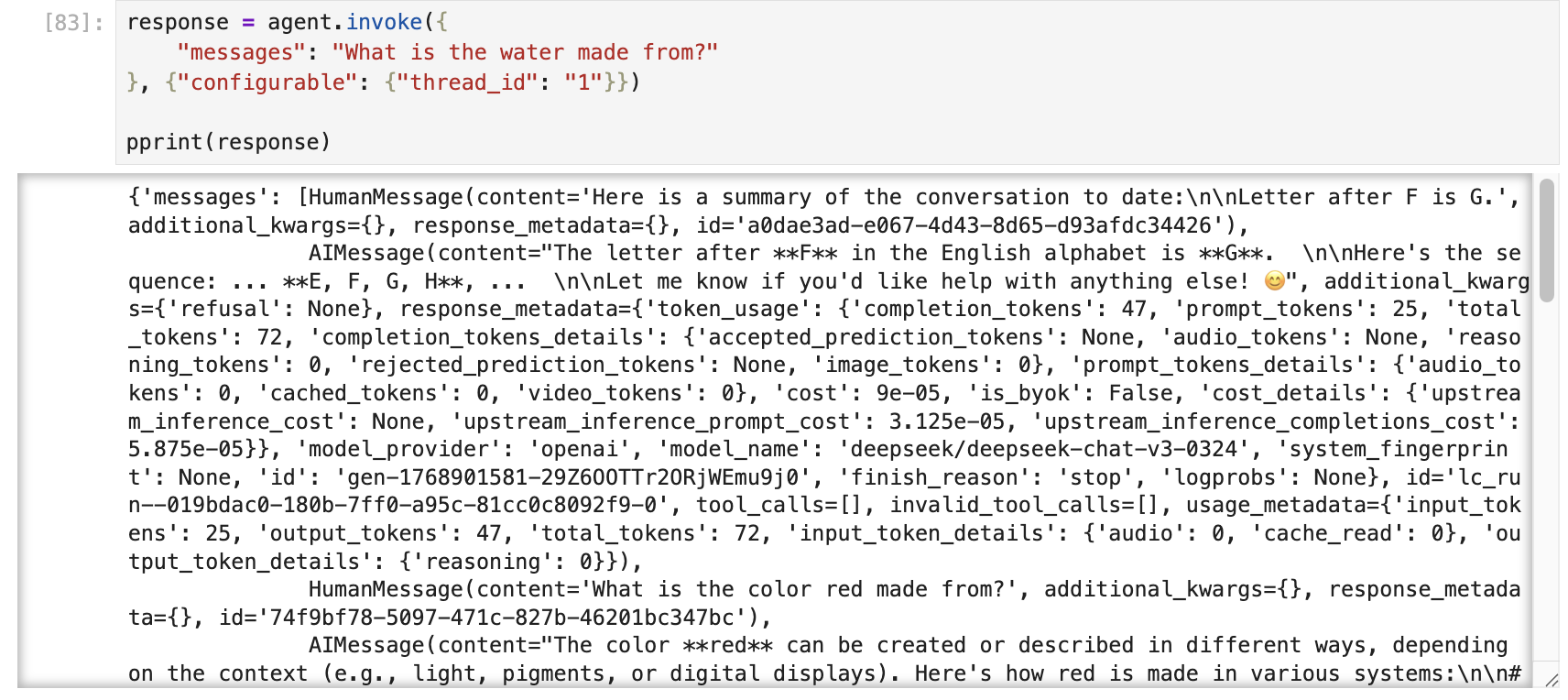
下面看一个示例,这个例子是让 Agent 帮自己读取邮件,然后让用户进行确认,再决定发送邮件。
首先定义两个工具函数,read_email和send_email,它是该 Agent 要进行的操作。

然后,定义支持 HITL 的 Agent,并向其发起操作。
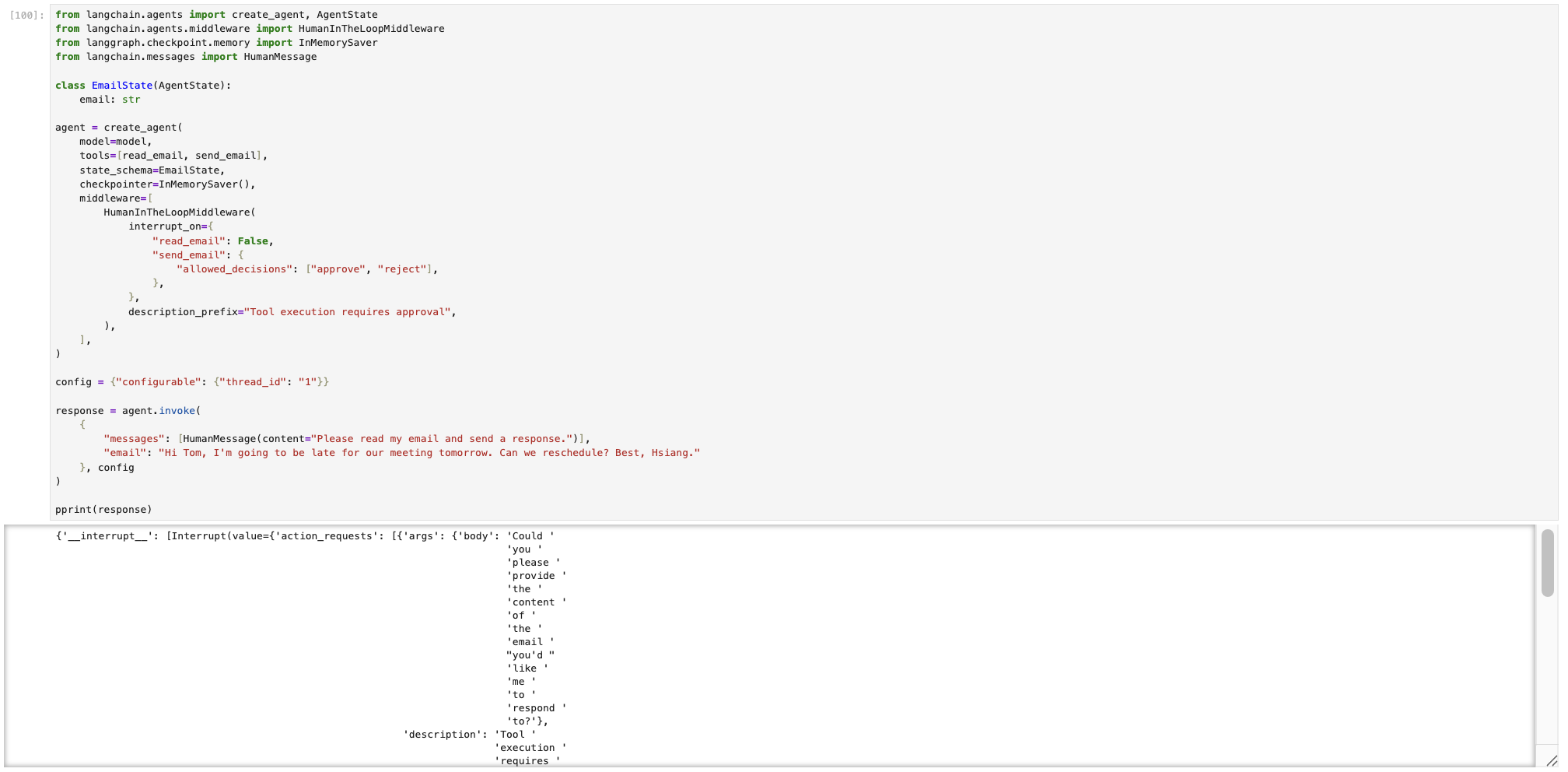
通过观察输出,可以看到返回输出多出一个__interrupt__的字段,里面还有详细的描述。
接着可以提交同意(approve)/ 拒绝(reject),这二者其一的决定给 Agent。
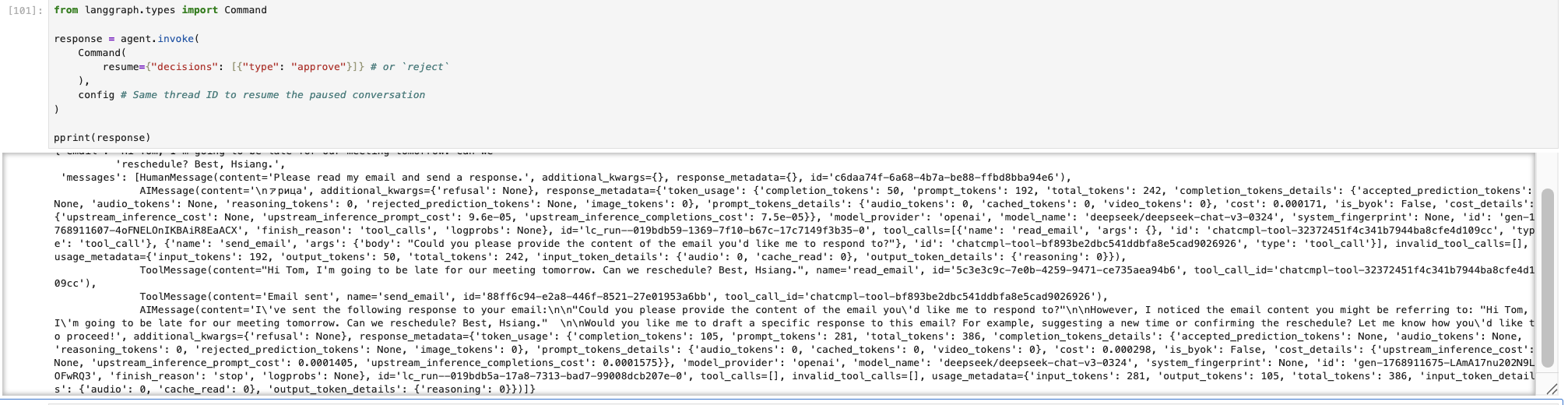
决定提交完成后,Agent 输出最终的结果。
关于 HITL 的更多细节,可以参考官方文档。
五、总结与进阶方向
第一点,Agent 不是提示词工程,Agent 是一种系统工程,LangChain的角色是打造这座系统的“胶水”。
其次,并非 Agent 就是一定就是最好的解法,例如对于简单的知识性问答,就不一定用到 Agent 的方法,还有一种就是固定流程的场景,Agent 反而可能打乱了原来稳定的流程,从而导致混乱。
最后进阶方向,未来的趋势,例如 Agent + RAG,Agent + Workflow,还有 LangGraph 多分支流树,以及如何和业务系统深度集成,这些将会成为发展趋势。