分布式服务系统设计概述
概述与定义
分布式系统是由一组通过网络协同工作的独立计算机(节点)组成的系统。它们共同完成一项业务目标,并对用户展现为“单一的系统”。从用户视角出发,分布式系统应尽量保持透明性:用户不需要知道请求被哪台机器处理、数据位于哪里,也不应感知到节点的增删与迁移。
一句话以概之:
分布式系统 = 多台独立的计算机,通过网络协作,对外表现得像一个系统
简要记住两点:
- 多节点协作完成同一业务目标。
- 对外表现尽可能像一个整体(透明性)。
注:分布式系统设计常常需要在一致性、可用性、分区容错(CAP)之间权衡,工程上普遍采用“最终一致性”的思路来换取高可用与可扩展。
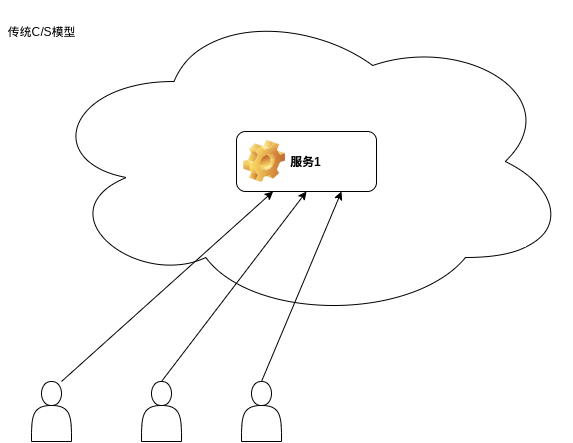
与集中式 C/S 架构对比
集中式(单体)C/S 架构示意:
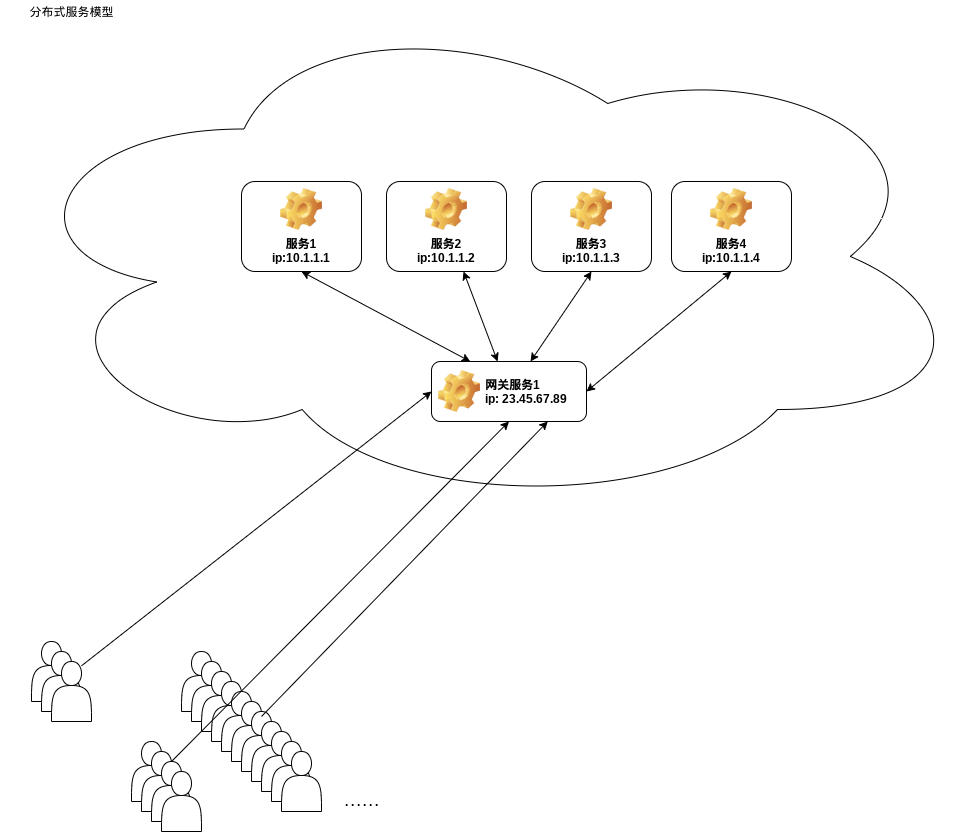
分布式系统常见形态:
分布式系统为什么“难”
单机系统的假设在分布式里全部失效 👇
单机你默认认为:
- 内存可靠
- 时钟一致
- 调用一定成功
分布式里现实是:
- 网络可能断
- 节点可能挂
- 时钟不同步
- 消息可能丢 / 重复 / 延迟
👉 分布式系统 = 在“不可信环境”下做可靠系统
分布式系统的核心问题(必须解决)
1️⃣ 通信
节点之间怎么说话?
- HTTP / RPC / gRPC
- 消息队列(Kafka / RocketMQ / RabbitMQ)
2️⃣ 状态一致性(最核心)
多台机器的数据怎么保持一致?
- 强一致(银行转账)
- 最终一致(点赞、推荐)
👉 这直接引出 CAP 定理
3️⃣ 容错
某台机器挂了怎么办?
- 副本(Replica)
- 自动切换(Failover)
- 重试 / 超时
4️⃣ 扩展性
访问量翻 10 倍怎么办?
- 加机器(Horizontal Scaling)
- 负载均衡(Load Balancer)
CAP 定理(分布式的“物理定律”)
在出现网络分区(P)时,C 和 A 只能选一个
- C(Consistency):一致性
- A(Availability):可用性
- P(Partition tolerance):分区容错(必须要)
现实系统:
- 金融系统 → CP
- 社交/推荐 → AP
设计思路总览
- 消息驱动:用消息作为服务间协作的“第一公民”,天然解耦,易扩展。
- Actor 模型:把服务实例抽象成 Actor,处理消息、维护自身状态,隔离并发。
- MongoDB/Postgres:模型适配业务对象,支持分片与分区或分集,利于扩展与提高高可用。
- Redis:作为读写热点的高速缓存,也可承担限流、短期队列等角色。
- Kafka/RocketMQ: 作为生产者/消费者的消息通道。
- 工程原则:边界清晰、单一职责、幂等与重试、尽量无状态(尤其是网关层)。
Actor 模型
Actor的理论性对应到实际工程场景其实就是具备自有状态的微服务子模块。
参考维基百科:Actor Model
Actor 是一个基本的计算单元:
- 接收消息(Mailbox)。
- 基于当前状态与行为处理消息(Behavior + State)。
- 产生新的状态与可选的响应消息。
Actor 之间彼此隔离,不共享内存,靠消息通信完成协作。这种模型特别适合高并发、强隔离的分布式场景。
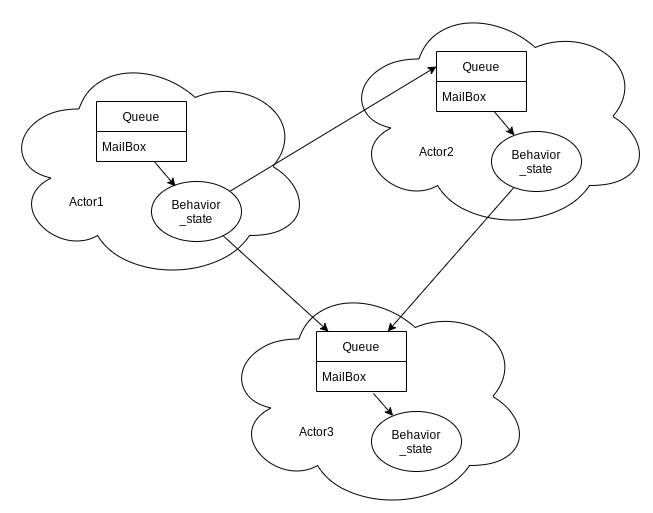
在系统分层中,可以把“服务 N”抽象为一组 Actor:每个服务被拆分为若干职责单一的 Actor,分别负责会话、订单、库存、结算等子域逻辑。这样既降低了耦合,也利于伸缩。
状态机(FSM)与 Actor
很多 Actor 内部可用有限状态机(FSM)来组织逻辑。FSM 的四要素:
- 状态(State)
- 事件(Event)
- 动作(Action)
- 变换(Transition)
状态机从“开始态”出发,在事件触发下迁移到下一状态并执行相应动作,最终到达“结束态”。把状态机视为一个“黑盒”,对外只暴露事件与结果,可以很好地实现内部信息隔离与状态安全。
数据层:MongoDB/Postgres
MongoDB 非常契合分布式系统:
- 数据模型(Document/Collection/Table)接近业务对象结构,读写自然。
- 分片(Sharding)为水平扩展而生,可把数据按键均衡分布到多节点。
- 副本集(Replica Set)提供高可用与读写分离策略。
- 一致性与事务:支持多文档事务,但工程上常以“最终一致性 + 幂等补偿”降低耦合与开销。
工程实践中的建议:
- 设计好分片键(高基数、写入均匀、查询命中高)。
- 结合副本集节点角色做读写策略(primary write,secondary read)。
- 用合理的索引与 TTL 索引管理热数据与历史数据。
要用好ORM,在Go语言中有个gorm很受欢迎。
缓存层:Redis
Redis 在该体系中的定位:
- 热点数据缓存:降低数据库压力,提升读性能(可用 Cache-Aside/Read-Through/Write-Through 等策略)。
- 短期队列与限流:基于 List/Stream/令牌桶实现简单队列与限流。
- 会话与临时态:存储短期会话、幂等令牌、分布式锁等。
注意典型风险与对策:
- 缓存穿透:为不存在的键增加空值缓存 + 布隆过滤器。
- 缓存击穿:对热点 Key 增加互斥更新或使用逻辑过期 + 后台刷新。
- 缓存雪崩:过期时间随机化,设置多级限流与降级策略。
服务发现与配置:etcd
etcd 是一个基于 Raft 共识算法的分布式键值存储,常用于服务注册与发现、动态配置与分布式协调:
- 服务注册与发现:
- 注册:实例以租约(Lease + TTL)的方式在
/services/{name}/{instanceId}下写入自身地址与元信息,并定期 KeepAlive。 - 发现:网关或调用方 Watch 对应前缀变化,感知实例上下线并更新本地路由。
- 健壮性:租约到期自动删除键,避免“僵尸实例”;客户端应实现指数退避与抖动重连。
- 注册:实例以租约(Lease + TTL)的方式在
- 动态配置:
- 将配置组织在
/config/{app}/{env}/前缀下,发布方写入,客户端 Watch 并热更新。 - 大体量配置建议拆分模块/分段加载;敏感配置需配合加密或专用配置中心。
- 将配置组织在
- 协调能力:
- 分布式锁/Leader 选举:使用 etcd concurrency API(基于会话的 Mutex/Campaign)。
- 典型用途:任务分片调度、单主写入、限流配额的集中仲裁。
- 运维要点:
- 集群规模以 3 或 5 节点为宜(奇数投票,过大反而降低写性能)。
- 合理设置快照与压缩(Compaction),避免 Watch Backlog 过大;对高延迟链路设置超时与心跳阈值。
在本文架构中,etcd 承担“服务注册与发现 + 动态配置 + 协调原语”的基础设施角色,辅助网关路由与内部服务寻址。
通信与一致性策略
- 通信方式: - 同步 RPC(HTTP/gRPC)用于强实时、强一致的小闭环。 - 异步消息总线用于解耦与削峰填谷(RocketMQ/Kafka/RabbitMQ/Redis Stream 等)。
- 重试与幂等:
- 下游短暂不可用时可重试;所有可重试的写操作必须幂等(去重键、幂等令牌)。
- 最终一致性:
- Saga/Outbox Pattern:用本地事务 + 事件外发保证变更可达,失败则编排补偿。
- 全局标识:
- 雪花算法/号段缓存生成可排序的分布式 ID,便于路由与审计。
消息中间件:RocketMQ/Kafka
RocketMQ/Kafka这类是高性能、低延迟的分布式消息中间件,具有完备的消息语义与企业级特性:
- 核心概念:Topic、Tag、Message Key、Producer Group、Consumer Group。
- 投递语义:默认至少一次(At-Least-Once),精确一次需在业务层通过幂等键/去重表实现。
- 顺序消息:基于分片键(Sharding Key)在队列内保证局部有序,适用于订单状态流、资金流水等场景。
- 事务消息:
- 流程:发送半消息(Prepare)→ 执行本地事务 → Commit/Rollback;
- Broker 可回查事务状态(Transaction Check)以防悬挂,生产者需实现回查接口;
- 常用于 Saga/Outbox 的可靠事件外发。
- 延迟/定时消息:内建多级延迟;配合重试策略实现柔性事务与削峰。
- 重试与死信:
- 消费失败按重试策略回投,超过阈值进入 DLQ(死信队列),便于排查与人工补偿。
- 消费模式:集群(负载均衡)与广播(全部消费);通常业务消费采用集群模式。
- 设计建议:
- 消息幂等:使用业务唯一键(如订单号)去重;消费者侧“先判重后执行”。
- 负载与扩展:按吞吐与有序需求规划队列数;避免消息体过大(建议 < 1MB),大对象走存储,消息只放引用。
- 可观测:开启消息轨迹与指标上报,关注堆积、耗时与回查比例。
在架构中,RocketMQ/Kafka 作为“事件总线”,支撑跨服务解耦、削峰填谷与最终一致性:
- Outbox:业务表 + outbox 表本地事务提交,后台发布到 RocketMQ,消费侧幂等入库。
- Saga:编排器基于事件推进/回滚步骤,失败走补偿消息。
拓扑与部署
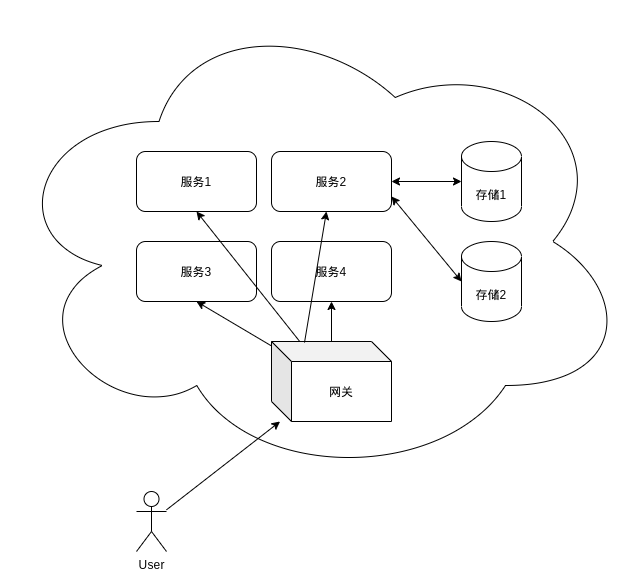
典型拓扑:
- 网关(Gateway):对外唯一入口,做鉴权、路由、限流与聚合。
- 服务注册与发现:基于 etcd 的注册表与 Watch,实现动态寻址与健康检查(也可配合 Sidecar)。
- 内部服务:按域划分的微服务/Actor 群组,互相通过 RPC/消息交互。
- 数据与缓存层:MongoDB 集群 + Redis 集群,结合副本集、哨兵与分片设计。
- 消息层:RocketMQ Broker 集群 + NameServer,按 Topic/队列扩展吞吐。
适用场景
- 大量并发接入(海量用户、IoT 设备、游戏网关等)。
- 数据规模庞大,需要水平扩容与弹性(日志/订单/内容平台等)。
- 对高可用有硬性要求(金融支付部分环节、核心交易读路径等)。
小结
这套“消息驱动 + Actor + MongoDB/Redis”的组合,工程路径清晰、生态成熟:当性能不够时通过增加节点扩容;当数据增大时通过 MongoDB 分片扩展;当读写压力不均时借助 Redis 缓存与限流削峰。真正的难点不在“能否工作”,而在“能否优雅地扩展与运维”。
下一步,我会在后续博文中结合具体的设计工具与代码,搭建一个“微型分布式服务系统”的端到端样例,覆盖服务拆分、通信、缓存、一致性与观测的最小闭环。